in resource-poor educational
contexts
Gergely Dávid
This article discusses a complex approach to
quality in language testing. It focuses on how the testing process may
be made more economical while maintaining its quality standards, how matching
techniques of standard setting and score computation can be found, and
how item-banks may be used, all in response to the need to balance quality
against increasing pressures on financial and human resources. Observing
the twin demands of quality and efficiency led to the formulation of an
agenda of what can be done: Go for the latest technology available while
some of the funding lasts, and maintain the quality of the testing effort
afterwards.
The context of the article is the Test of Language Competence (TOLC), an advanced level language competence examination in English, developed by the Centre of English Teacher Training (CETT) at Eötvös University (ELTE) in 1992. It is a two-level proficiency test, and passing TOLC One and TOLC Two constitutes a minimum requirement for entering the second and third year of studies respectively. Throughout this article, examples of data and solutions will be taken from TOLC, and references will be made to the work over the past 9 years.
The notion of quality
Quality does not simply mean something `good' or `better than the others' because two very different entities may be good according to their own standards. A basic economy car is as acceptable as any other car as long as it is as economical. Similarly, a luxury car is expected to be as luxurious as other cars of the same category. In management science, this requirement has been formulated as `conformance to specifications'. Quality may be brought about "by reducing uncertainty and variability in the design and manufacturing process" (Evans and Lindsay, 1999, p. 12), which are "the chief culprits of poor quality" (p. 72). Thus, this notion of quality allows for differences between the tests different examination boards produce, but demands consistency and that the `identity' of a particular language test be kept the same over time: different versions of the same test should be comparable to the highest degree. If a test does not fulfil this quality requirement, the minimum pass score cannot be interpreted to represent the same level of language competence in subsequent versions of the same test.
In modern management science, attention has moved from putting quality control personnel at the end of the production process, from checking whether the goods and services at the output are of the right standard to monitoring the processes involved, so that only top quality goods and services are produced (Pike and Barnes, 1996; Evans and Lindsay, 1999). Focus on the process in testing is perfectly in line with the awareness that a language test is a lot more than a product (test structure, tasks and items, criteria and score conversion tables etc.). In addition to the product, certain processes also need to be specified in terms of the preparation and piloting or pretesting of test material, test administration, analysis, and decision making.
Quality control in language testing
Given the negative connotations of the term `control', `quality assurance' or `quality management' may be suggested as better alternatives to quality control. Though `controlling' has a directive ring to it, in resource-poor contexts language testers may have to adopt techniques which are highly interventionist in nature. Since proficiency tests are most often used to inform educational decisions and present high stakes for the candidates, active quality control, assurance or management is needed. Whichever term is used, there should be colleagues to check whether all the scripts and scoresheets have been returned after rating, whether raters have done their work reliably and whether items have performed well or not. As will be seen below, quality controllers may have to use reliability information to ask certain scripts to be remarked or even raters to be excluded from the rating. They may also use information from item analyses to discount poorly performing items or intervene in various ways in order to be able to interpret the results with confidence, as if a lot more resources had been allocated to the test.
Language testing is expensive due to its highly contrived nature. As a result, it is often the case that a lot less is done than what would be possible to ensure the quality of the tests. In an East-central European context, there is an academic tradition of excellence (Enyedi & Medgyes, 1998), which is favourable to the values that quality control assumes, but efforts to improve quality often come up against the scarcity of resources. Professionals on the Hungarian scene constantly have to fight to keep their innovations going and to make achievements sustainable. Those in the field of testing get a perspective on achievements on the international scene, which generates ambitions and expectations of professional excellence, but the wartorn state of education makes their efforts seem like sacrifice. Thus, in a Hungarian context, the language tester's work may be thought of as a balancing act between the demands of quality and the pressures from limited financial and human resources.
Quality control and measurement
Conventionally, the hallmarks of test quality have been the twin requirements of reliability and validity. Reliability may be defined as the consistency with which a test performs its measurement function and the degree to which measurement is error free (Henning, 1987; Bachman, 1990). A standard definition of validity is that it concerns the extent to which a test measures what it is designed to measure (Hughes, 1989). Although professionals often refer to the reliability and validity of the test, neither is a property of the test itself. Reliability is a property of the scores (Bachman, 1990) while validity, according to Messick (1988, 1995, 1996) and Bachman (1990), is the extent to which the inferences or decisions made on the basis of test scores are meaningful, appropriate and useful. Thus, attention to reliability and validity implies that a good deal of work needs to be done towards the end of the testing process, when the scores have already been obtained.
There is a good measure of agreement between professionals in the field in that reliability is a necessary but insufficient precondition for validity (Alderson, Clapham & Wall, 1995; Bachman, 1990; Henning, 1987; Hughes, 1989). Given the relationship, the improvement of the reliability of measurement should increase the validity of the test. Monitoring reliability is difficult enough because it demands advanced technical expertise, appropriate software and computers. Monitoring validity demands even more: it demands the interpretation of reliable data. It demands both quantitative and qualitative approaches; the marshalling of evidence in as many ways as possible to support or reject a particular interpretation or use of tests scores (Messick, 1981). In resource-rich contexts, the professional imperative calls for the monitoring of reliability and the permanent collection of validity evidence in various ways. In resource-poor contexts, however, the question is whether it is possible to go a long way validating test scores through the improvement of reliability. This article makes an attempt at showing how far validation can go, through the improvement of reliability in a resource-poor educational context.
The measurement of language competence, especially if the test includes a number of communicative components, is only possible through the observation of some language performance because language competence, being an internal quality, is not directly observable. The performance context of a language test, however, contains features which are not related to language competence. The most obvious of these include the person and personality of the examiner, or rater, and various features of the test task, or item, (type of task, topic etc.) and last but not least, the characteristics of the candidate. As a result, a point scored must be assumed to reflect the impact of these features of performance.
The performance features of the testing context prevent perfectly reliable measurement. If a comparison were possible with perfectly reliable scores, which would represent the true competence of the candidates, performance features would add extra points to the score of some candidates, while they would subtract some points from the true scores of other candidates. Statistically speaking, such imperfect measurement often results in a fairly large margin of measurement error, according to classical test theory. Traditionally, analyses of variance (ANOVA) and factor analytical studies were the tools to show whether there were significant performance features at work or not.
One of the more recent developments in measurement is the possibility of breaking down this large error component because it is not all random error. A sizeable part of the error includes systematic patterns. If an examiner consistently gives higher scores to male or female candidates, there is an error in the measurement, but it is systematic, so it should be possible to account for it. Similarly, if, seeing the difficulty of a particular task, the examiners raise the scores they award on one task but not on other tasks, there will be systematicity in the error. Thus, if features of test performance are successfully identified, random error may be broken down into a number of systematic factors and a much smaller random error component. Hence the increase in reliability and, potentially, validity. The developments were made possible by the advent of probabilistic approaches to measurement.
It would appear that the choice of a particular language competence model as the basis of a language test is little related to its quality control aspects. A modern measurement approach, however, that can identify and take into account performance features is a better vehicle for extended models of language competence, which include performance features, than for models that do not. Bachman's model of Communicative Language Ability (CLA) is one such model because it includes such features as: knowledge of the world; strategic competence; psychophysiological mechanisms and the context of situation in addition to a model of tacit language competence. By contrast, some older models such as Canale and Swain's (1983), for example, admittedly do not attempt to include features of language performance. Very consciously, they hold back from broadening their model to include an ability for language use, beyond communicative language competence, saying that it "has not been pursued rigorously in any research on communicative competence" (p. 7). Therefore, it may be argued that an advanced measurement model actually allows language testers, through item-banking as is described below, to put into practice extended models of language competence which are often discussed but which language testers, for want of appropriate measurement tools, have shied away from implementing.
Quality control and the testing process
Quality control in language testing is complex, and entails a number of different components. Some of these components, such as the training of examiners and the production of good items, may be more obvious to the reader than others. This article is intended to focus on process components, the significance of which is perhaps less obvious to many in the language education field. It is to deal with how the testing process may be made more economical while maintaining quality standards, how institutional standards may be set and what methods of score computation may be used to the same end. It is also to explore how item-banks may be used to relieve pressures on scarce resources.
Quality assurance for TOLC
TOLC is a two-level proficiency test for English B. Ed. students at
CETT, ELTE. It was introduced in 1992 as a complex examination of proficiency
in English. The exam tested grammar, vocabulary and all the four skills
separately and included ten papers altogether. Considering the scarcity
of resources, the testing team have often asked themselves whether they
had `bitten off more than they could chew' with TOLC. In recent years,
due to staffing shortage that has gone from bad to worse, there has been
insufficient staff time available to run a comparatively large proficiency
test and the financial resources to support it have become inadequate.
A quote from an early draft of Dávid et al. (1996) shows that the
conflict between professional excellence and resources was there from the
beginning.
The testing team were in conflict with themselves. On the one hand, they were raised in a traditional culture of excellence which prompted them to do their jobs conscientiously and to the best of their abilities, whereas the harsh realities of finances, the pressure from a foreign culture of professionalism on the other hand, pulled them in another direction. They were also aware that western aid is not likely to be long term. In this way, it was also difficult to expect long term commitments from staff. How to decrease staff overload and costs associated with TOLC without destroying it as a comprehensive proficiency test and its validity was to become a recurring theme in the evolution of the examination. Here lay a potential vicious circle in that without the investment of a large amount of time and other resources, test results would be less and less professionally defensible and convincing to the sceptics and the test would not be able to fulfil its role as a quality control device. Once this is the case, the point of having an exam at all may be called into question.
Such a description should sound familiar to many throughout the
Hungarian higher education system. In similar situations, a number of soft
options might be suggested. One might be chipping away at the time and
care with which a proficiency test should be prepared. Another might be
reducing the size of the examination, dropping task types or whole papers
altogether until what is left is no more than a multiple-choice English
test. Chipping away at the investment of time and care flies directly in
the face of ethical considerations. High stakes tests being what they are
demand that decisions of pass and fail be supported in a professionally
defensible way. Reducing the size of the examination, in the manner of
peeling an onion beyond recognition, is equally indefensible because the
remaining test would be scarcely more than a glorified achievement test,
and it would not be possible to claim to have tested language competence.
The selected solution was to work on quality assurance in three areas,
namely test construction, setting passmarks and item banking.
Selected techniques of quality control
In the following sections of this article selected areas of quality control will be reviewed, to show how a proficiency test might contribute to maintaining departmental standards.
Test construction
At the inception of TOLC, the testing team at CETT followed the advice of foreign consultants. What they delivered was the standard model of test construction, supposedly practised by large examination boards (Figure 1).
Figure 1 The standard model of test construction
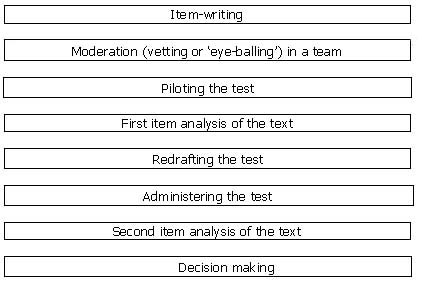
Most sources (Hughes, 1989; Alderson et al., 1995; Bachman and Palmer, 1996) prescribe the standard model of the test construction process shown in Figure 1, which may be conceived of as the orthodoxy in the field. This model is supposed to maintain the quality standards of the test by prescribing consecutive phases of action. If they are adhered to, however, it is expensive in terms of money, time and effort.
One of the most expensive stages of the standard model is that of piloting language test material on comparable groups of students. In addition, it should also be noted that even if the test items are properly piloted and good results are obtained, there is no absolute guarantee that the same good performance results will be obtained when the test is administered in real testing circumstances. This is because in order to do the piloting, the language tester has to choose a group (sample) of students from the target population itself, and this sample must be representative of the targeted population in all possible ways. Needless to say that this is very difficult to do, simply because the sample group will most likely be a natural group in a specific school or course, from a specific social and geographical background.
The vagaries of piloting
CETT is not a large examination board and has never had comparable resources. Indeed, the report of one of the consultants in 1993 is full of references to the difficulties colleagues experienced in trying to do everything `by the book' (Clapham, 1993). There is little in the literature on what should be done if piloting is not sustainable. One of the major difficulties was finding comparable student populations. Staff indeed tried travelling to other universities in Hungary, which naturally was expensive in terms of money and time. Also, student communication between universities was something to worry about so the staff tried `piloting in disguise', without disclosing which institution they were from. Students, however, are smart, and they were beginning to suspect by the end of the session what the visitors were up to. Not heeding the consultants' warning, `distance piloting' was also tried, resulting in utter failure when the piloting was either not done out of forgetfulness or was done with the wrong groups or items.
Modifying the testing process
It was thus clear by 1994 at the latest, that the standard model of test development was not sustainable. Some colleagues were of the opinion that they were good enough item writers already; there was no need for piloting anyway. However, the value of analysing the performance of items, being a rich source of learning for the test constructor, was perceived. Thus, it was decided that the standard model of test construction must be adapted to suit the Hungarian context and the resources available.
The adapted model of test construction
The chief feature of the adapted model is that it skips the phase of piloting before the administration of the test (Figure 2), but includes post-test methods instead, as a professionally defensible substitute for piloting. The performance of the items is to be analysed only after the test has been administered. In a post-test analysis, items that do not perform well are not only identified but are neutralised as well, by discounting them in successive rounds of analyses from every student's score. It is not possible to say how many items must be discounted because it depends on the results of the first analysis. The language tester should stop before the reliability of the test falls, not because there are not any more poor items but because the test is beginning to be too short to be reliable. The advantage is that after the test has been administered, one is not working with a sample of students only, whose adequacy can always be called into question. In post-test analyses, the analyst works with data from the target population or a real test sample of candidates so inferences about a similar yet different group of students do not need to be made.
Also, the post-test technique increases the discrimination of the remaining items in the test. Higher discrimination is achieved because high achievers and low achievers usually differ in how they respond to misleading items. Due to their abilities, high achievers tend to get into overcomplicated lines of thinking and may eventually get the answer wrong. Responding to the same kind of item, low achievers often resort to a strategy of guessing, which, surprisingly enough, frequently serves them well. In this way, post-test analyses prevent high achiever students from losing points unfairly, and they also prevent low achievers from scoring undeserved points (evidence in Dávid, 2000). The rationale behind post-test analyses is thus consistent with broader requirements of discrete-point tests in that test-takers should get both the right and wrong answers for the right reasons as well as measurement requirements in that the margin of error should be decreased. In this way, post-test analyses are not only useful in preventing a decline in the quality of tests, once piloting is not done; they are a way to further improve test quality and validity.
Figure 2. The adapted model of test construction

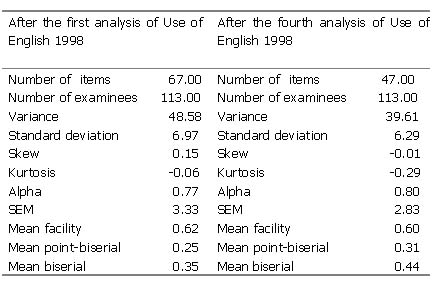
Until 1999 the criteria on the basis of which test quality was analysed were standard classical item analysis criteria. These most notably included the variance and standard deviation, internal consistency (Alpha), the standard error of measurement (SEM) and two discrimination indices (the mean biserial and point-biserial). Items to be discounted were identified as those which had negative discrimination values or those which had positive but very low values approximating 0. The relevant performance indicators of one of the papers are presented in Table 1. On the left are the results of the first analysis in which 3 items from a total of 70 were discounted. The column on the right shows the same performance indicators after 23 items have been discounted after the fourth analysis. It is up to the decision of the language tester how many rounds of analyses produce the best results. Naturally, beyond a certain point test quality will worsen simply because there will be too few items in the test. The test on the basis of which students were scored was shorter, but it may be considered an improved measurement device on all but one of the criteria above.
Table 1. 1st and 4th classical analyses of TOLC Use of English 1998
The reader might also have observed that the techniques of post-test analyses were restricted to the discrete-point papers of TOLC. Indeed, these techniques were first developed for the discrete-point papers of TOLC (Listening, Use of English). At the time, CETT only had the software and the expertise to analyse discrete-point type tests. Apart from that, there were two additional reasons why post-test analyses were first applied to the discrete-point papers of TOLC.
1. Controlling the quality of discrete-point tests was seen as more critical to the quality of the test because the test taker in such tests is not in a position to negotiate the meaning of the item. Unlike tests such as interview tests of speaking, in which the meaning of the participants' input is typically and actively negotiated (Katona, 1996), the hallmark of a good discrete-point type test is that such negotiation does not take place at all.
2. The difficulties of doing proper piloting affected the discrete-point papers first and foremost because due to the requirements of the software (MicroCAT, 1988), they need to be tried with at least 25 students, which is more than the typical size of a language class in Hungary. It follows, then, that piloting a discrete-point test requires at least two study groups, which presents organisational difficulties. However, from 1999 onwards post-test techniques could also be extended to the criterion-referenced papers of TOLC as part of the item-banking framework which will be discussed later.
Standard setting and score computation
Another important problem the language tester faces is that of setting the passmark. He must determine how good a performance is good enough. Determining the passmark as a fixed percentage of the total score is clearly a norm-referenced solution, which should be unacceptable to all those advocating criterion-referenced methods of assessment. Determining the passmark as a point score fixed in advance is scarcely anything different. It is just as arbitrary because it completely ignores the fluctuation in test difficulty or abilities and such performance factors as the raters' impact on the scores. Language testing practice in Hungary, as some of the language examination documentation reviewed in the accreditation process shows, has sadly and typically remained faithful to identifying a particular percentage of the aggregated raw scores or to a tradition of fixing passmarks in advance of the test. It might be asked, as Alderson et al. (1995, p. 160) do, how these exam boards are able to cope with unexpected difficulty or easiness in the test across different versions of the test. The passmark should be the numerical expression of the institutional standard. Information should be collected of what constitutes acceptable performance and what does not, and it should be mapped onto the scale of scores on which pass and fail decisions are made.
Setting valid standards may not be achieved without attention to how the scores are actually computed (Bachman and Palmer, 1996, p. 224; Messick, 1988, p. 43). Aggregating the candidates' performance in a composite score, in which the scores from all the papers are summarised has its pitfalls. Complex tests that include discrete-point type papers (typically listening, reading and use of English) in addition to criterion-referenced integrative ones (characteristically tests of speaking and writing) automatically assume that once at least some of the papers are criterion-referenced, the aggregated overall passmark is criterion-referenced too. It is not because the overall score scale is no more than a ruler on which an appropriate passmark must be found.
Another trap is the need to weight individual papers, without which differences in the character of the task types (a use of English test, for example, with the highest number of items) might make the measurement of one trait (skill) dominate over the others. Even when only equal weighting is the goal, information from the individual papers is often not successfully balanced. Discrete-point tests typically need to contain a large number of items, while integrative papers with criterion-referenced marking are typically assessed on the basis of considerably fewer criteria. In response to this problem, scores from the discrete point papers are often weighted down, compressed according to some conversion table. Thus, much useful information, hard won, is lost. It may be concluded that the double job of interpretation, i.e. turning language performance into numerical data and then turning the numbers into levels and pass and fail decisions is riddled with potential points of distortion. A way out of the quagmire may be to abandon raw scores as the units in which scores are calculated and reported. Two such systems were developed for TOLC in the past.
In the 1992 model of TOLC, passmarks were determined on a paper- by-paper basis. That reflected a segmental view of language competence in that students had to achieve a score higher than the passmark on each paper in order to be able to pass. Thus, the score computation method represented the view that students must have a minimum of all-round competence. The individual differences of those who passed were honoured in the differences of the 2-to-5 pass grades (Dávid, 1995b). It was essentially a profile type of score reporting because an overall passmark was not calculated. From 1994 onwards, the testing team began to lean towards a `compensatory' (or holistic) view of language competence. The compensatory view is based on the idea that even equivalent speakers of a foreign language all have different strengths and weaknesses. From 1995, scores from individual papers were combined into composite scores, and students either passed or failed TOLC on the basis of those. In this way, it may be stated as a rule of thumb that two above average scores were usually sufficient to compensate for a third, below the average score, but one above average score was not sufficient to compensate for two weaker ones.
Both the segmental and compensatory views are viable and defensible approaches. There does not seem to be a theoretical way to decide which view is more satisfactory. From the `gate-keeping' angle, it may be stated that the segmental view was more valid because it suggested that no matter how proficient a certain candidate might be in listening, for example, he or she must also meet the minimum requirements in the other papers as well. From a feasibility angle, it appears that the holistic view of `judges' (see below) may be more easily and convincingly expressed on a scale of composite scores than on a number of separate test paper scales. In sum, the score computation method, while expressing the essence of the avowed view of language competence, should avoid distortions and making measurement unreliable.
Standard setting techniques
Judgements and statistical techniques are both indispensable to standard setting. As will be seen below, statistical techniques have been most useful in the conversion of raw scores into computable standard scores and the computation of the final results for TOLC, whereas judgements provided the much needed criterion-referencing element in the standard setting process, as in Livingston (1978) and Alderson (1993).
Originally, the foreign consultants suggested a methodology of standard setting (Alderson 1993, also in Popham 1981) that appealed to the testing team. Using this method, several staff were asked to be `judges' and identify, on the basis of a holistic impression, a `borderline' candidate in their classes, that is, a student who could as easily fail as pass TOLC. These staff were then asked to give percentage estimates of this student's chances of correctly answering each task or item in each paper of TOLC. The estimates were used to determine the lowest number of questions a student must answer correctly on each paper to pass. Because the candidates used to make these estimates were borderline, their test results would represent the minimum CETT standard.
Whereas this standard setting method theoretically matched the perceived needs, in practice it produced results which were unsatisfactory. The judges underestimated the borderline students, who reached considerably higher scores. Trying to identify the reasons for the problems, Dávid (1995a) came to the following conclusions.
1. Providing estimates of percentage chances that the borderline student had in getting the correct answer on discrete-point type tasks, the judges did not include the percentage of the chance that the student had anyhow, even by making uninformed guesses at the answers. (The chance that a student has in guessing the answer correctly for a four-option multiple-choice test item, for example, is 25%.) In all probability, this mistake was the reason why the judges uniformly underestimated the borderline students.
2. The judges had a holistic view of the borderline student they identified. They did not have a definite enough concept of the abilities in the receptive skills (reading and listening), but only of the productive skills (speaking and writing) abilities. The judges, due to the nature of teaching, may have had a direct impression of their students' speaking and writing skills because they saw them speak in class and read their homework. They did not have a similarly direct impression of their listening and reading skills.
The finding that judgements on separate papers proved unsatisfactory because the judges had a holistic view of their students rather than a compartmentalised one (separate `listening competence', `speaking competence' etc.) strongly suggests that valid decisions of pass and fail could not be made on the basis of compartmentalised, paper-based judgements (Dávid, 1995a). Nevertheless, the judgement technique was retained in a holistic form.
Score computation techniques
The chief feature of the development of the score computation techniques for TOLC was the transition from reporting scores in raw form to a different system in which students obtain one point for one correct answer to a single question, but the results are reported on a different scale. Three such systems have been used for TOLC to date.
The initial score computation mechanism of TOLC (model 1992) was crude and rather basic. Scores from the different papers were all converted to a scale of 20. The conversion dealt successfully with the problem of weighting and avoided some of the traps involved in reporting raw scores, but information was lost in the papers for many items. From 1995, the raw scores were first converted to standard scores (z scores), which were scaled afterwards to obtain scores that looked more palatable to students and staff than unscaled z scores would have (Brown, 1988). The appeal of the standard scores approach lay in increasing the comparability of test paper scores, by artificially normalising the distribution of scores in each paper. This is important because model 1992 was an extensive test of autonomous papers where information was not pooled or summarised in a single parameter. The drawbacks of reporting scores in z scores should also be described. Z scores are a function of the mean and the standard deviation, both central measures of a distribution. This makes z scores sensitive to slow changes in the mean language ability of a relatively small population of students, as is the case in the CETT programme. As it was possible to diagnose an erosion of mean language ability after 1996, department standards could not be maintained using z scores. The answer to the problem was to proceed to the third system: item-banking.
Item-banking
Concern about diminishing resources and standards made the testing team try yet another approach to ensure the quality of the testing effort at CETT. It was a project to develop banks of items for each paper. It needs to be said immediately that item banks are more than mere collections of items. In the testing profession, the term item-bank is used with a variety of meanings, which range from the simplest, in which an item-bank is scarcely more than a cupboard in which items are stored, to the most complex, in which, tests are constructed and analysed on the basis of the previous performance of available items. Item-banks are stocks of items which have already been tried, having either been piloted or used once. Thus, the distinguishing feature of item-banks is that items are calibrated, i.e. their performance features (difficulty, discrimination etc.) are known (Lengyel, Andor, Berényi, Borgulya, Dávid, Fekete, Heltai, Németh & Völgyes, 1999).
When it is known how items in a particular test performed, they are part of the bank and the information can be used in the design of new tests. In this way, an item-banking project also holds out the possibility of using the items again in later years. By recycling items, item-banking may be a cost-, resource-efficient as well as a standardised way of running exams. The item-bank would eventually help produce items of appropriate difficulty without `recreating' the whole test from scratch for each testing period 1. To start item-banking, appropriate statistical tools are needed.
The computer software Bigsteps (Linacre & Wright, 1995) is designed for discrete-point papers in which there are only two variables: the abilities of students and the difficulty of items. It cannot analyse data from oral or writing tests because in these, in addition to the difficulty of the tasks and student abilities, raters constitute a third variable. For three or more variables, a different programme, such as Facets (Linacre, 1998) should be used, which, used in combination with Bigsteps, makes it possible to do item-banking for a test package that includes discrete-point type papers as well as criterion-referenced ones.
It is usually not possible to build such analytical capabilities up within a very short time. Apart from the software, experience must be accumulated over time, which demands a good deal of experimentation. While the testing team for TOLC had already developed more and more sophisticated analytical techniques for discrete-point type items, there were no comparable developments for the oral and writing papers until 1999.
Making meaningful comparisons
It is intuitively known by teachers that no task can be designed as perfectly equivalent to another in terms of difficulty and other characteristics even if a detailed blueprint is applied. Similarly, no amount of training can produce, or `clone', perfectly equivalent raters with equal `severities' either. Yet, if interchangeable versions of a particular test task is worth the same number of points in a language test, it amounts to assuming that these versions are truly equivalent in difficulty. It is also known that the same number of points awarded by different raters do not indicate identical severities or identical candidate performances (Douglas, 1994). In this way, comparisons on the basis of simple raw scores are not meaningful enough. In fact, it may be accepted in principle that each individual task and rater has its own innate difficulty and severity, which, however, cannot be measured directly. Instead, having elicited it through performance, they may be estimated with high precision using probabilistic methods.
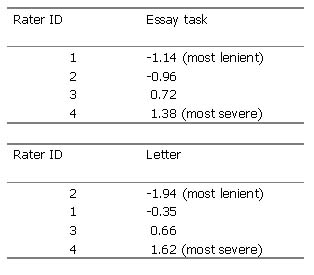
Table 2. Differences in the severity of CETT raters (year 2 oral interactive data, 1999)
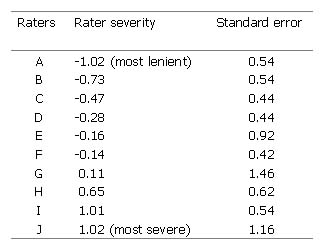
In the tables above, CETT raters are shown to have different degrees of severity (Table 2). Oral interactive tasks were also shown to have differences in their difficulties in Table 3. Also, there appears to be a certain degree of consistency in raters' severity. In two different year 2 writing tasks marked by the same raters an almost identical order of rater severity may be established (Table 4). If rater severity differences show consistent patterns, it will be possible to establish some raters as lenient and some as strict.
Table 3 Differences in the difficulty of tasks (year 2 oral interactive data, 1999)
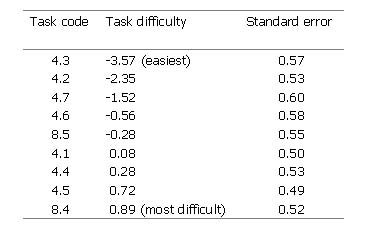
Table 4. Similar rater severities measured on two year 2 writing tasks, 1999
If task difficulty and rater severity can be calculated, they can also be taken into account in the calculation of the candidate abilities, the third variable. It is possible to compensate in the ability score for both the difficulty (or easiness) of the task and the severity (or leniency) of the rater. Estimates of student ability based on the same raw point scores may thus differ because a student who was examined on one of the harder tasks and/or by one of the hard raters, for example, will have their ability score raised. Conversely, a student who was examined on one of the easier tasks and/or by a lenient rater will tend to have their ability score lowered.
Applying the new technology in a comprehensive way permits comparisons that have either not been possible before, or if they have been possible, they were extremely complicated and labour intensive as well as the source of contentious decisions. Put simply, it is possible to compare student performance as if all students have done the same tasks (items) and have been rated by the same rater. In an educational context, there are three ways in which meaningful comparisons may be made.
1. Comparison of student performance across different tasks and raters within the same administration of the test;
2. The comparison of student performance between different versions of the test, to make sure that scores obtained on different versions of the same test reflect comparable performances. An example might be the need to apply the same yardstick to first-takes and retakes of TOLC. The testing team need to be able to tell whether students who fail in the June administration, for example, show noticeable gains in their language ability by the next January;
3. The comparison of performance of candidates in successive test administration or years, i.e. the comparison of the language competence of students of year 1999 with that of 2000 and 2001 in the CETT context, for example, to see if the standards of the student intake and the training programme are maintained. In this way, it is possible to compare candidate performance longitudinally, i.e. to trace the performance of students as they progress through the programme and to see whether real development takes place or not.
Comparisons within the data from a single administration of the test is readily available through computer analyses, while between datasets from different versions of the same test (comparisons no. 2 and 3) a linking technique called `anchoring' may be used (Woods & Baker, 1985). With this, it is possible to locate all items, raters and candidates in the same system of coordinates. It is also possible to convert passmarks determined in earlier years to scores obtained in the current year. The significance of such passmark conversions is that the laborious standard setting procedure does not have to be started all over from scratch every year. In this system, analyses yield scores in logits, not coerced by the number of raw scores obtainable in different papers and without losing valuable information.
Special difficulties
The significance of being able to estimate student ability, task difficulty and rater severity is perhaps most obvious in the case of an oral test because the oral demands more resources in terms of tasks (if it is task-based) and raters. The need to develop probabilistic methodologies for oral tests may be the most pressing because the number of tasks and raters needed is large, relative to the number of tasks and raters in other papers. The need to use a large number of tasks and raters limits the comparability of student performance because, according to language testing conventions, the larger the number of raters and tasks involved in the marking of a group of candidates, the weaker the comparability of the candidates' performances becomes. In such a context, reliable measurement is still a possibility because Facets (Linacre 1998), for example, makes 250 rounds of comparisons before it finalises student abilities.
Ability to cater for task options
There has been a tendency at CETT to use a number of task options, different essay titles, for example, for a particular TOLC paper. The proponents of options argue that it does not matter which option any one student chooses and whether it is difficult or not. According to these views, raters can assess the students' language competence confidently, irrespective of any differences of option difficulty. Their arguments are supported by the fact that the marking criteria are not task specific in that the descriptors do not include specific references to task options. Some staff, however, have been sceptical and wary of the practice of offering options, saying that it is dangerous to assume that option difficulty can be so easily neutralised.
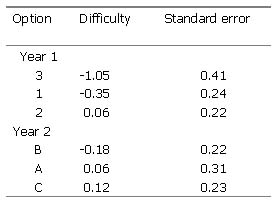
The new technology has shown, on the one hand, that there may be mostly significant if not very large differences in the difficulty of year 1 writing options. The differences in the difficulties of year 2 options are larger, and all of them are significant (see Table 5 on the other side of the page). Now that option difficulty differences have been empirically substantiated, it may be stated that CETT should only continue to use task options if the new technology is applied as part of the quality control system of TOLC and if scores are calculated to compensate for differences in task difficulty. The chief argument of those who advocated the use of options may be reconciled with the arguments of those who were worried about maintaining appropriate measurement conditions: Students may be allowed to demonstrate their language competence on tasks that suit them most, which would allow, at the same time, taking into account differences in option difficulty.
Table 5 Different option difficulties obtained on the TOLC 1999 year 1 and 2 writing tasks
A role for quality exams in a changing paradigm
The trend of the lower language competence standards of incoming CETT students at ELTE might well indicate an emerging new paradigm. This is the reason why the example of quality assurance for TOLC is expected to be relevant to other English departments. In the `old days', at least in the field of arts and social sciences, a successful entrance examination meant that the degree at the end of studies was almost guaranteed. Very few students were failed but low numbers of failures did not, of course, mean that standards were low. With the size of higher education growing, and with the financial pressures on universities, the entrance examination may gradually lose its screening function. The emerging new paradigm might be similar to that in a number of western countries where the screening takes place during the university programme.
Thus, it is logical to expect that TOLC-type proficiency exams will have to take over this screening function at certain points in the curriculum. While trends may still change, they nevertheless point to the need for strengthening internal quality control in all English departments. For the language competence dimension, CETT-ELTE have TOLC in place. Given a good measure of dedication and an openness to developments in the field, high standards are achievable in educational contexts where resources are scarce.
Notes
- There is a good deal more to be found on item-banking, its theoretical background and the techniques needed to build and operate item-banks (Alderson et al., 1995; Bachman, 1990; Henning, 1987; McNamara, 1996; Popham, 1981). [back]
References
Alderson, J. C. (1993). Judgments in language testing.
In D. Douglas, & C. Chapelle (Eds.), A new decade in language testing
(pp. 46-57). Alexandria, VA: TESOL.
Alderson, J. C., Clapham, C., & Wall, D. (1995).
Language
test construction and evaluation. Cambridge: Cambridge University Press.
Bachman, L. F. (1990). Fundamental considerations
in language testing. Oxford: Oxford University Press.
Bachman, L. F., & Palmer, A. S. (1996). Language
testing in practice. Oxford: Oxford University Press.
Brown, J. D. (1988). Understanding research in second
language learning. A teacher's guide to statistics and research design.
Cambridge: Cambridge University Press.
Clapham, C. M. (1993). ELTE-CETT testing project. Draft
report of visit 21 April to 1 May. Mimeo.
Dávid, G. (1995a). From judgements to institutional
standards at CETT Budapest. Paper presented at the 2nd Teachers Develop
Teachers Research Conference, Cambridge, January 5-7, 1995.
Dávid, G. (1995b). Memorandum on standard setting
for TOLC. Unpublished Mimeo.
Dávid, G., Major, É., & Moya, S.(1996).
Testing people: Testing language competence at CETT. In P. Medgyes, &
A. Malderez (Eds.), Changing perspectives in teacher education (pp.
87-96). Oxford: Heinemann.
Dávid, G. (2000). The use of Multitrak items and
a small-group oral in the context of the Hungarian higher education. Unpublished
Ph.D. thesis, University of Glamorgan, Wales.
Douglas, D. (1994). Quantity and quality in speaking
test performance.
Language Testing 11, 125-143.
Enyedi Á., & Medgyes P. (1998). State of the
art: ELT in Central and Eastern Europe. Language Teaching 31, 1-12.
Evans, J. R., & Lindsay, W. M. (1999). The management
and control of quality. Cincinnati, OH: South-Western College Publishing.
Henning, G. (1987). A guide to language testing: Development,
evaluation and research. New York: Newbury House Publishers.
Hughes, A. (1989). Testing for language teachers.
Cambridge: Cambridge University Press.
Katona, L. (1996). Negotiated oral test discourse in
Hungarian EFL examinations. Unpublished Ph.D. thesis. Eötvös
Loránd University Budapest.
Lengyel, Zs., Andor, J., Berényi, S., Borgulya,
Á., Dávid, G., Fekete, H., Heltai, P., Németh Zs.,
& Völgyes, Gy. (1999). Az államilag elismert nyelvvizsgák
akkreditációjának kézikönyve. Budapest:
Professzorok Háza.
Linacre, J. M. (1998). Facets: Rasch measurement computer
program. Version 3.1 [Computer software] Chicago: Mesa Press.
Linacre, J. M. & Wright, B.(1995). Bigsteps. Version
2.57. Rasch-model computer program. [Computer software] Chicago: Mesa
Press.
Livingston, S. A. (1978). Setting standards of speaking
proficiency. In J. L. D. Clark (Ed.), Direct testing of speaking proficiency:
Theory and application (pp. 257-270). Princeton, NJ: Educational
Testing Service.
McNamara, T. (1996). Measuring second language performance.
Harlow:
Longman.
Messick, S. (1981). Evidence and ethics in the evaluation
of tests. Research Report. Princeton, NJ: Educational Testing Service.
Messick, S. (1988). Validity. In R. L. Linn (Ed.), Educational
measurement
(pp. 13-103). New York: American Council on Education/Macmillan.
Messick, S. (1995). Validity of psychological assessment.
American
Psychologist 50, 741-749.
Messick, S. (1996). Validity and washback in language
testing. Language Testing 13, 241-256.
MicroCAT item and test analysis program. Version 3.00.
[Computer Software] (1988). St. Paul, MN: Assessment Systems Corporation.
Pike, J., & Barnes, R. (1996). TQM in action.
A practical approach to continuous performance improvement. London:
Chapman and Hall.
Popham, W. J. (1981). Modern educational measurement.
Englewood Cliffs, NJ: Prentice Hall.
Woods, A., & Baker, R. (1985). Item response theory.
Language
Testing 2, 117-139.
Dávid Gergely is TOLC coordinator at CETT. He has taken an interest in language testing for 15 years and has been a member of the Language Examinations Accreditation Board since 1998.